什么是网络爬虫?网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。
内容一般分为两部分,非结构化的文本,或结构化的文本。
1. 关于非结构化的数据
1.1 HTML文本(包含JavaScript代码)
HTML文本基本上是传统爬虫过程中最常见的,也就是大多数时候会遇到的情况,例如抓取一个网页,得到的是HTML,然后需要解析一些常见的元素,提取一些关键的信息。HTML其实理应属于结构化的文本组织,但是又因为一般我们需要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作才能得到,所以还是归类于非结构化的数据处理中。
常见解析方式如下:
•CSS选择器
现在的网页样式比较多,所以一般的网页都会有一些CSS的定位,例如class,id等等,或者我们根据常见的节点路径进行定位,例如腾讯首页的财经部分。

•XPATH
XPATH是一种页面元素的路径选择方法,利用Chrome可以快速得到,如:
1.2 一段文本
一篇文章,或者一句话,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储,如果是需要实时提取有用信息,常见的处理方式如下:
分词
根据抓取的网站类型,使用不同词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词为方向,词频为长度。
NLP
自然语言处理,进行语义分析,用结果表示,例如正负面等。
2. 关于结构化的数据
结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据就可以了,提取JSON的关键字段即可。
3、爬虫爬取网页的基本步骤
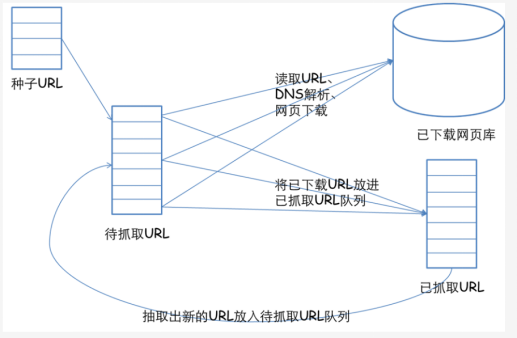
1) 人工给定一个URL作为入口,从这里开始爬取。
万维网的可视图呈蝴蝶型,网络爬虫一般从蝴蝶型左边结构出发。这里有一些门户网站的主页,而门户网站中包含大量有价值的链接。
2) 用运行队列和完成队列来保存不同状态的链接。
对于大型数据量而言,内存中的队列是不够的,通常采用数据库模拟队列。用这种方法既可以进行海量的数据抓取,还可以拥有断点续抓功能。
3) 线程从运行队列读取队首URL,如果存在,则继续执行,反之则停止爬取。
4) 每处理完一个URL,将其放入完成队列,防止重复访问。
5) 每次抓取网页之后分析其中的URL(URL是字符串形式,功能类似指针),将经过过滤的合法链接写入运行队列,等待提取。
6) 重复步骤 3)、4)、5)。

4、主过程组成
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
【控制器】
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
【解析器】
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
【资源库】
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、Sql Server等。
5、补充:
开源爬虫小知识
﹡DataparkSearch是一个在GNU GPL许可下发布的爬虫搜索引擎。
﹡GNU Wget是一个在GPL许可下,使用C语言编写的命令行式的爬虫。它主要用于网络服务器和FTP服务器的﹡镜像。
﹡Heritrix是一个互联网档案馆级的爬虫,设计的目标为对大型网络的大部分内容的定期存档快照,是使用java编写的。
﹡HTTrack用网络爬虫创建网络站点镜像,以便离线观看。它使用C语言编写,在GPL许可下发行。
﹡ICDL Crawler是一个用C++编写,跨平台的网络爬虫。它仅仅使用空闲的CPU资源,在ICDL标准上抓取整个站点。
﹡JSpider是一个在GPL许可下发行的,高度可配置的,可定制的网络爬虫引擎。
﹡LLarbin由Sebastien Ailleret开发;
﹡Methabot是一个使用C语言编写的高速优化的,使用命令行方式运行的,在2-clause BSD许可下发布的网页检索器。它的主要的特性是高可配置性,模块化;它检索的目标可以是本地文件系统,HTTP或者FTP。
﹡Nutch是一个使用java编写,在Apache许可下发行的爬虫。它可以用来连接Lucene的全文检索套件;
﹡Pavuk是一个在GPL许可下发行的,使用命令行的WEB站点镜像工具,可以选择使用X11的图形界面。与wget和httprack相比,他有一系列先进的特性,如以正则表达式为基础的文件过滤规则和文件创建规则。
﹡WebSPHINX(Miller and Bharat, 1998)是一个由java类库构成的,基于文本的搜索引擎。它使用多线程进行网页检索,html解析,拥有一个图形用户界面用来设置开始的种子URL和抽取下载的数据;
﹡WIRE-网络信息检索环境(Baeza-Yates 和 Castillo, 2002)是一个使用C++编写,在GPL许可下发行的爬虫,内置了几种页面下载安排的策略,还有一个生成报告和统计资料的模块,所以,它主要用于网络特征的描述;
﹡Ruya是一个在广度优先方面表现优秀,基于等级抓取的开放源代码的网络爬虫。在英语和日语页面的抓取表现良好,它在GPL许可下发行,并且完全使用Python编写。按照robots.txt有一个延时的单网域延时爬虫。
﹡Universal Information Crawler快速发展的网络爬虫,用于检索存储和分析数据;
﹡Agent Kernel,当一个爬虫抓取时,用来进行安排,并发和存储的java框架。
未来,最贵的东西将是数据。所以,掌握爬虫技术非常重要。
真的所有网站都可以爬吗?
看不懂??
什么网站都可以爬嘛?
= =有点看不懂
很酷的样子哦